

 2026-01-06 10:00
2026-01-06 10:00 2025年12月22日,长城汽车发布魏牌蓝山智驾进阶版,完成了VLA上车元年的收官。
这一年,理想、小鹏、奇瑞和长城都已经推出了自己的VLA量产车型,小米、零跑等公司也有相关布局。
VLA显然成为了2025年的汽车圈热词。它得益于深度集成进神经网络的“视觉-语言-动作”模块,可以像GPT一样对驾驶行为进行深度思考,通过“直行变为红灯-红灯需要停车-控制刹车”的逻辑推理,和人类一样凭借认知去开车。

10月底,一张手机拍摄的PPT照片突然在网络疯传,显示FSD V14已加入思维链
事实上,特斯拉经历完表现平平的FSD V13,也选择放弃坚持两年的端到端路线,FSD V14版本已改为类似VLA的架构。
这也是针对FSD V13的黑箱困境——即使参数量相比V12提高3倍,仍然无法杜绝闯红灯、逆行等低级问题。
特斯拉FSD引入VLA之后,小鹏汽车董事长兼CEO何小鹏近期也是亲赴北美体验,随后公开喊话FSD V14和特斯拉Robotaxi已经没有区别,L2和L4可用同一套系统实现。
理想汽车智能驾驶研发高级副总裁郎咸朋也发文表示,VLA就是自动驾驶最好的模型方案。
但即使如此,VLA的反对声音依旧不少。
“华为不会走向VLA的路径,我们认为这样看似取巧,其实并不是走向真正自动驾驶的路径。华为更看重WA,也就是World Action,中间省掉language这个环节。”华为智能汽车解决方案BU CEO靳玉志说道。
这指向的正是VLA的最大弊端,依靠语言模型进行推理,就需要视觉到语言、语言到动作的两次翻译,而翻译就会导致误差,反应也更慢。何小鹏也曾坦言:“一段1200多字的文字描述,也无法精准地‘翻译’一个十几秒视频。”
因此,有人认为“世界模型“才是未来。可以将这理解成是一种极致的端到端,既能用输入信息直接映射输出结果,又完全理解真实世界的运行规律,瞬间响应且完全可靠。
只是做出这样一个模型,需要给它灌输和世界有关的全部知识(参数量),再用难以计数的算力支持思考。因此,世界模型目前还只能部署在云端,难以上车。
“我认为想要做百辆无人车以上,世界模型最关键,对其他公司可能做VLA模型卖车最关键,大家选择不同的路线是因为目标不同。”小马智行CTO楼天城表示。
NO.1
[ 端到端很颠覆,但并不完美 ]
2023年8月26日,马斯克在个人社交账号开启了一场45分钟的直播:乘坐一辆老款特斯拉Model S游览旧金山,自己只做安全员,交给仅有2000多行代码的FSD Bate V12系统驾驶。

FSD Bate V12误闯红灯,马斯克随后接管
从他全程举起的手机视角可以看到,这辆Model S顺利通过无保护左转、斑马线、施工区域等复杂场景,遇到行人还可以等待让行,几乎可以应对全部路况,只有一次红灯没有停车而被接管。
这种能力在当年还很少见,只是大家更关心另外一个问题:为什么2000多行代码就能做出这样的效果?之前那么多年都在干什么?
“V12系统从头到尾都是通过AI实现。我们没有编程,没有让程序员写任何一行代码来识别道路、行人等。全部交给了神经网络。”马斯克在直播时回应。
他所指的编程代码正是人工规则,这也是提升早期智驾系统能力的原始途径。
当时采用的分治算法,就相当于一个“人工智障”机器人,只有执行能力,无法自主思考。
所以,想让它认识一个物体,知道红灯应该停车,都需要像对待“智障”一样,通过人工规则一条一条的教会它。教会的越多,能力也就越强。直到2024年,依然有人采用这种路径。
根据何小鹏2024年AI Day上的说法,如果要做到无限接近人类驾驶员的水平,需要大约10亿条规则,而当时稳定的系统只有10万条左右,相当于只完成了万分之一。
也就说明,想通过人力穷尽所有场景,写完所有规则,着实有些异想天开,所以特斯拉转向了端到端。
chib p s,singh p. recent advancements in end-to-end autonomous driving using deep learning:a survey
比起分治算法,端到端就聪明多了,能像小孩子一样拥有模仿学习的能力。因此,不再需要依靠人工规则死记硬背,给它观看大量人类的驾驶视频,就能自发将环境和驾驶行为联系起来,找出“这种场景下,应该这么做”的规律。
端到端的架构也非常简化。尤其是特斯拉的一段式,从传感器图像输入到控制指令输出,中间只经过深度学习模型,取消了全部人工规则,代码量骤减99%。
尽管这是一个更有前景的方案,但同样存在弊端:只能看到观测到输入和输出两组数据,中间工作就像在一个不透明的黑色箱体里进行,完全不可见,出现错误也就难以追溯到是哪个环节导致的。
这也是困扰端到端的一个主要问题,传统方案每一步运算清晰可见,出现问题可以直接优化具体模块。而端到端出现问题,因为不清楚出错的地方,就只能不断投喂正确应对这一场景的优质视频片段,祈祷它能照着学习。效率低不说,效果还不可控。
所以,如果想解决这个问题,是不是可以想办法将它的决策过程翻译出来?基于这种思路,最先出现的是端到端+VLM。

理想汽车端到端+VLM
VLM即视觉-语言模型,相当于给端到端套了一个思维链“外挂”:同步接收传感器、导航等输入数据,利用语言模型(类似GPT)的推理能力,生成类似“路口变为红灯,应该减速停车”的场景描述和处理意见,给端到端的行为做出备注,极端场景或许还能参考它的靠谱决策。
这种方式解决了端到端缺少显式表达的问题,但VLM本质上还是一个独立运行的模型,跟不上端到端的节奏(端到端做完5次决策,VLM可能只来得及生成1个文本)。
因为运算的慢,VLM的决策虽然最终也会传给端到端,但非复杂场景都会直接忽略,仅作为棘手问题的兜底,联合训练和优化也没预想中那么好做。
如果参照“感知-判断-决策-控制”智能驾驶传统框架,VLM其实只能覆盖前三个阶段,缺乏对控制过程的理解。要是问题出在控制上,VLM就会因为看不懂控制信号这种“外语”,无法分析原因,进行优化。
因此,一个看起来更加合理的架构就出现了:再加上生成控制信号的能力,就可以打通最后一环,通过自动化的数据闭环,实现低成本、高效率的自我迭代了。
这就是VLA视觉-语言-动作模型。
NO.2
[ VLA一边拆黑箱,一边加重担 ]
如果用一句话描述:VLA既有全程可求导的端到端神经网络形式,又有大语言模型的推理能力。
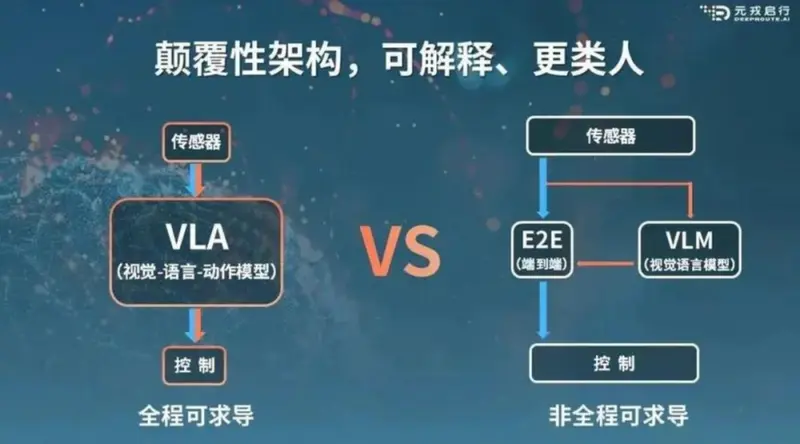
元戎启行对比VLA与端到端+VLM
能力上,它可以看做VLM的进化,补全了动作特征的对齐。动作解码器(A)的引入,使语言模型不必再局限于生成类似“向右变道”这种难以对应为轨迹的文本,而是可以换成一种更加简洁高效,代表方向盘转角、刹车幅度等具体动作的特性向量,消除了自然语言和控制信号间的语义鸿沟。
这也意味着从感知到控制的每一个步骤,都是采用了可微分的数学计算,没有了之前的抽象语义理解过程,做到了推理过程的全程可求导。在遇到不如预期的驾驶行为时,就能从控制信号反向追溯错误源头,进行优化。
架构上,它又与VLM有着本质的不同。视觉感知、语言理解和动作生成都不再是外挂模块,而是深度集成进统一的神经网络,因此语言模型也可以顺理成章发挥更大作用:原本只是解释端到端的行为,现在已经集成进模型中,不如直接让它来主导决策。
这样的提升无疑是巨大的,语言模型擅长推理,可以像老司机一样用脑思考决策。而传统端到端只能不断拟合视频片段中的行为,寻找表面规律,缺乏底层的智能逻辑。
2025年,VLA已经出现了爆发式增长,理想、小鹏、奇瑞和长城等都已经走在这条道路上。就连最早将端到端落地到车的特斯拉,也引入了类似的架构——通过全景分割结果、3D占用结果、3D高斯渲染结果、语言信息等中间输出结果,对最终轨迹进行推理。
既然得到了广泛认同,那VLA能否成为智能驾驶的最终解呢?也不尽然,它仍然存在短板。
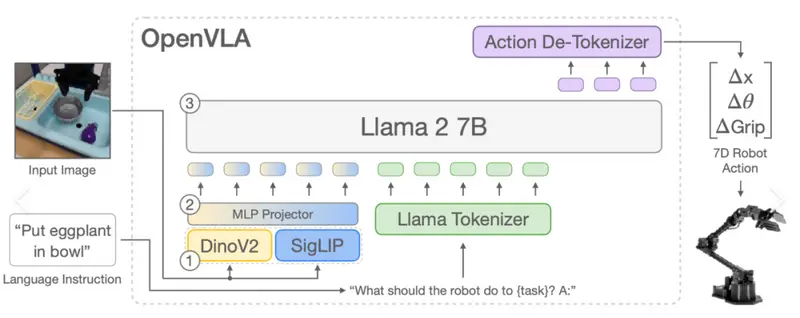
OpenVLA模型架构
VLA依赖于中间的大语言模型,而语言模型只能理解和输出token(可以是自然语言,也可以是一串符号),所以处理每一帧画面,就需要一次将“全部输入数据转化为token进行推理,再将token转化为控制信号”的完整过程。
然而,不管是传输数据、token转化,还是推理过程,都会带来巨大的算力消耗与带宽吞吐量压力,这恰恰是追求毫秒级响应的智驾系统最不想看到的。
以理想为例,曾经布置在单颗Orin-X芯片上的VLM只能以3Hz左右运行,MindVLA虽然换上了新一代Thor-U,并通过MoE架构、Sparse Attention等稀疏化设计降低推理负担,但也只提升到10Hz左右,和传统端到端的运行频率差距仍然明显。
实际上,这已经是VLA摒弃自然语言,转而采用一种信息含量更高、能隐式表达的抽象token,从而显著降低算力开销和延迟后的结果了。只是,这种token虽然具有更高的保真度,但仍无法避免原始信息的损失。
何小鹏曾举例量化这一过程的难度:“VLA模型中间涉及两次语言转换,这会带来大量信息损耗。比如,一段1200多字的文字描述,也无法精准地‘翻译’一个十几秒视频。”
一些热门AI视频创作者也有类似的抱怨,用语言还原自己想象中的画面非常困难。即使是仅有几秒的特效视频,也要用写满一整页Word的文字去约束生成效果,而这第一次得到的往往还不是想要的画面,还要再调整很多回。
NO.3
[ VLA会是最终路线吗? ]
尽管目前还没有达成未来路线的共识,但已经出现了很多新的尝试。
第一个方向是保持VLA路线,但要破解现有问题。
理想汽车针对VLA算力消耗大、运行频率不足的痛点,已经提出了降低模型精度,将运行频率提高到20Hz的想法。
这种优化逻辑可以简单理解为:目前主流的FP8/INT8精度,每个计算节点都需要占用1字节资源。优化为FP4精度后,仅需0.5字节即可完成同等运算,相当于在相同硬件资源与时间成本下完成翻倍任务,间接让TOPS(每秒能执行的基本操作次数)提升1倍。
这一想法的出现,也是因为英伟达首次在智驾芯片的架构层兼容了FP4精度。如果实现,可由目前INT8和FP8混合推理精度下的700TOPS稠密算力,提升至近3倍的2000TOPS(需要配合稀疏优化)等效稀疏算力。
只是,目前业界还缺乏能被认可的FP4标准格式,贸然降低精度容易造成模型性能崩溃,还是一个漫长的技术攻坚。
第二个方向是针对现有架构的问题,直接在架构层做出调整。

小鹏准备在下季度发布的VLA 2.0方案,将架构从V-L-A改成了V/L-A。
这样带来的好处是,VLA 2.0不再依靠语言模型进行推理,输入和输出数据都不用再进行额外的token转化。而是和传统端到端一样,输入传感器数据,直接就能映射出控制信号,不仅显著减低延迟,还能减少两次翻译中的信息损耗。
华为WA车端世界行为模型则走了另外一条路,VLA是通过大语言模型解决端到端的黑箱问题,而WA则是在端到端的映射过程中,引入多模态输入和MoE多专家能力,通过 “信息补全” 和 “逻辑约束” 降低不确定性。
多模态输入很好理解,核心是通过综合多种类型信息,增加对周围环境的了解渠道。这样在决策时,就可以用多源数据进行交叉验证,缓解黑箱问题。
另外,端到端黑箱问题也集中于超出训练的极端场景,而华为在ADS4.0上增加了更多的激光雷达、4D毫米波雷达等传感器,实际也有助于在这类陌生环境中捕捉到关键特征。通过多模态输入,也能减小模型的推理盲区。
MoE则是一种分布式的架构设计,它将传统的单一大模型,拆分成一个门控网络和多个专家模型。工作时可以单独调用对应的专家模型,无需激活所有参数。这些将会带来两个直观好处。
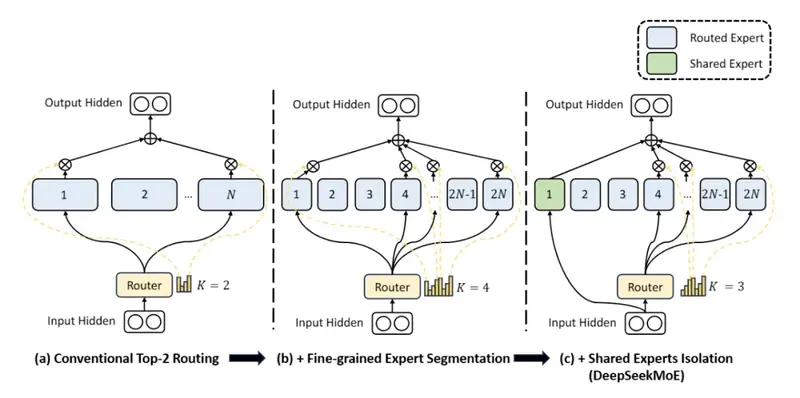
DeepSeekMoE架构
第一是,不同于传统单一大模型倾向于平均行为,难以兼顾所有情况,每个专家模型都可以独立训练,专精于某一类特定场景或技能。这样在处理一些复杂问题时,就能调用最适配的专家,摆脱单一模型的 “通用妥协”,从而提高长尾场景的适配能力与决策精度。
第二是,MoE的稀疏激活机制,使总参数量限制也得到了缓解。原本的单一大模型要严格受到车端芯片算力限制,而MoE只需要保证被调用的部分专家能流畅运行即可。这意味着,被调用专家的参数量之和,就可以逼近传统单一大模型的总参数量,通过扩容使性能增强,同样可提高决策的准确性。
华为智能汽车解决方案BU CEO靳玉志认为,VLA是一种取巧方案,不是真正走向自动驾驶的路径。华为更看重WA世界行为模型,用多模态输入数据直接生成控制信号,省掉所有的语言转译环节。
NO.4
[ 写在最后 ]
除了现有的流派,宇树科技创始人、CEO、CTO王兴兴还提出过另一个方法:生成一段动作视频,然后让机器人去模仿执行。他认为这一路线可能比VLA发展更快,收敛概率更大。
这正是通过世界模型实现自动驾驶的概念:根据输入画面,运用物理规律过滤冗余信息,推理出未来发生的众多可能,然后寻找出最优路径,生成这段未来场景的长视频,再让车辆照做。
只是这有个必要前提,想让生成的视频可靠,放心交给车辆执行,就要模型拥有真正理解物理世界的能力,也意味着需要异常夸张的参数量和算力支持。
以小鹏为例,其部署在云端的世界模型参数量已经达到720亿,需要3万卡算力集群,而车端VLA即使通过三颗图灵AI芯片拥有2250TOPS算力,也只放了几十亿参数量。
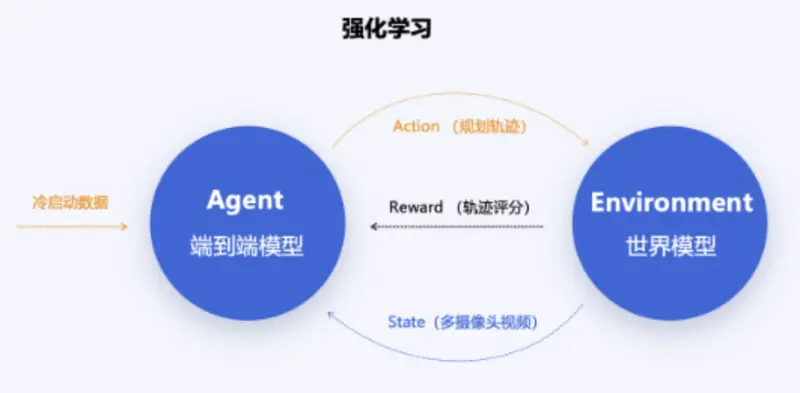
商汤绝影强化学习路线
因此,世界模型现阶段主要还是用于车端模型的仿真训练。比如,主动生成现实中难以采集到的极端场景进行强化学习,提高系统的泛化能力;设立一个奖励函数,让系统决策在安全、效率和舒适等因素之间找到最优轨迹。
这种方式也确实取得了比较理想的结果,通过世界模型解决困扰已久的长尾场景收敛问题,要比依靠现实场景的数据闭环高效得多。而布局世界模型也已成为了目前自动驾驶界最为统一的行为,无论车端采用的是哪种方案。
实际上,这也反映出了另一个层面的问题,大家对于新技术从来不是抗拒的,只是出于市场竞争的需求进行标签化。而在背后,不同路线的框架已经有了很多相同的部分,就像很多人都在用云端世界模型、MoE架构,小鹏VLA 2.0也能和华为WA一样直接映射结果。
不同的路线,似乎不是看起来那样水火不相融。







